Qwen3-TTS :开源界最强实时可控多语言 TTS 来了!
最近AI语音合成领域又炸了锅——阿里巴巴通义千问团队在 2026 年 1 月 22 日正式开源了 Qwen3-TTS 全家桶,同时放出了完整的技术报告
/upload/07bf72be-3885-4c38-9e68-2e61bed88707.pdf 。这不是又一个“能说话”的模型,而是目前开源社区里在质量、可控性、流式延迟、跨语言稳定性上最全面碾压的存在。简单一句话:用3秒音频就能克隆声音 + 用自然语言描述就能捏出全新声音 + 首包延迟低至97ms + 支持10种语言长篇稳定生成,而且全开源( Apache 2.0 ),这几乎把之前只有商用闭源系统才能做到的体验直接拉到开源社区了。
下面我把技术报告的核心内容浓缩成一篇博客,方便大家快速 get 到重点。
Qwen3-TTS 到底有多强?一句话总结亮点
3秒零样本声克隆:参考音频只要3秒,就能高保真复刻说话人(跨语言也稳)
自然语言声控:直接写提示词就能捏新声音、改语气、情绪、语速、风格(e.g. “用温柔的御姐声读一段恐怖故事”)
超低延迟流式:12Hz版本首包延迟97ms(0.6B)/ 101ms(1.7B),真正实时对话级别
训练数据:超500万小时多语言语音,覆盖中文、英文、日韩、德法俄葡西意等10种语言
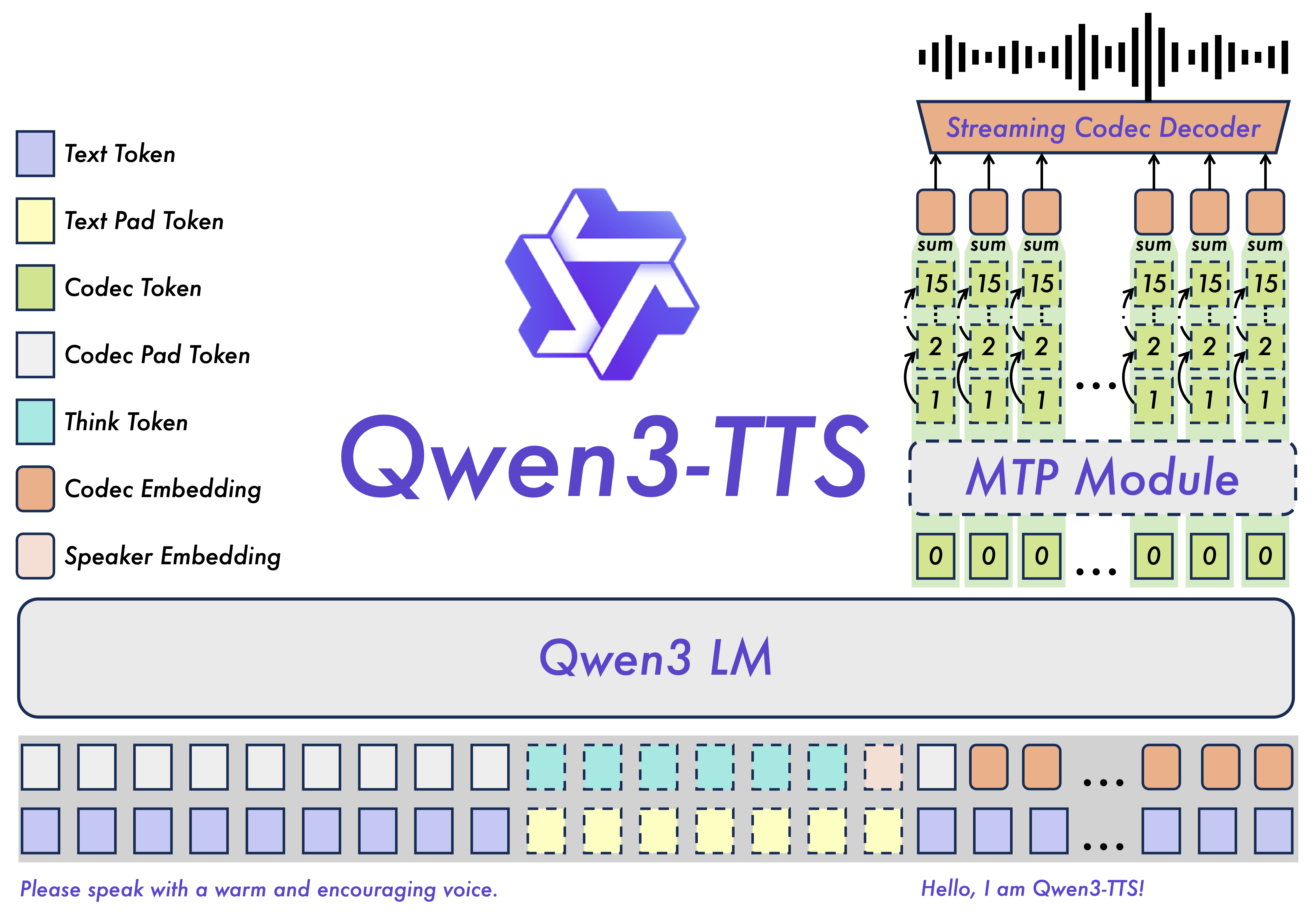
双 tokenizer 设计:
25Hz单码本:语义+声学融合,适合高保真长语音
12Hz多码本(语义+15层声学RVQ):极致压缩 + 轻量ConvNet解码,延迟最低
架构:基于Qwen3的双轨自回归 LM + Multi-Token Prediction(MTP) ,文本 token 一来就同步预测语音 token
一句话:Qwen3-TTS把“AGI级语音合成”的门槛又拉低了一大截。
模型家族一览(目前已开源的 12Hz 系列)
注:技术报告里还提到了 25Hz 系列,但目前开源主力是 12Hz 超低延迟版,25Hz 高保真版后续会跟上。
实验数据有多炸?(直接抄报告 SOTA 表)
零样本克隆( Seed-TTS benchmark )
Qwen3-TTS-12Hz-1.7B → 英文WER 1.24(最低),中文WER 0.77
说话人相似度(SIM)在 10 种语言全部第一,吊打MiniMax、ElevenLabs、CosyVoice 3等商用/开源 baseline。跨语言克隆( CV3-Eval )
中→韩 WER 从 CosyVoice3 的14.4% 暴降到 4.82%(降幅66%)
英→中、日→英、韩→日 等方向也大幅领先。指令控制( InstructTTSEval )
VoiceDesign 1.7B 在描述相似度(DSD)、韵律一致性(RP)、音频质量(APS)上全面领先开源,甚至部分维度超GPT-4o-mini-tts。长语音稳定性( >10 分钟)
25Hz-1.7B-CustomVoice → 中文长测WER 1.517,英文 1.225
几乎无重复、无遗漏、无明显断层,远超分段式系统。Tokenizer重建质量( LibriSpeech test-clean )
12Hz版拿下PESQ_WB 3.21、STOI 0.96、UTMOS 4.16、SIM 0.95,全方位新SOTA。
为什么它能做到这么强?
训练三段式:通用 500 万小时 → 高质量 CPT 去噪 → 长上下文 32k token
后训练:DPO 对齐人类偏好 + GSPO 规则奖励 + 轻量说话人 SFT
流式设计:12Hz tokenizer + 纯左上下文因果解码 + MTP 多 token 预测 → 第一帧就出声
可控性:继承 Qwen3 的强文本理解 + 训练中引入“思考链”模式,复杂描述也能听懂
怎么玩?(立即上手链接)
最后想说
2026 年初的开源 TTS 已经进化到这个地步:延迟低到能做实时 AI 伴侣,控制细到能写小说台词直接生成配音,长语音稳到能播客整期不用剪辑,质量高到听不出是 AI 。
Qwen3-TTS 不是“又一个 TTS ”,而是把门槛彻底打穿,让个人创作者、虚拟主播、游戏配音、多语种客服等场景都能用免费开源方案做出商用级效果。
如果你是做内容、做AI应用、做语音交互的,真的建议现在就去拉模型玩一玩——很可能下一个爆款语音产品就从你的 demo 开始。